Linux内核:进程管理 |
您所在的位置:网站首页 › linux 32位 uefi › Linux内核:进程管理 |
Linux内核:进程管理
|
【推荐阅读】 一文看懂linux内核详解 linux内核内存管理-写时复制 深入了解使用linux查看磁盘io使用情况 概述在32位linux系统中,每一个进程拥有3GB的虚拟内存空间,所有进程共享1GB的内核空间。对每一个进程来讲,都有一个task_struct结构体,包含该进程的所有信息,其中就包括最为重要的mm_struct,它提供了进程在内存布局中的所有必要信息。 相关的数据结构mm_struct操作系统运用了面向对象的思路对mm_struct进行封装,Linux就是通过mm_struct实现了内存管理。一个进程的虚拟地址空间主要由两个数据结构进行描述,一个是mm_struct,另一个是vm_area_struct。mm_struct描述的是虚拟地址的整体空间,vm_area_struct描述的是虚拟地址空间的一个区间(子集)。可以说,mm_struct结构是对整个用户空间的描述。 在进程的task_struct结构体中包含一个指向mm_struct结构的指针,mm_struct用来描述一个进程的虚拟地址空间。进程的mm_struct则包含装入的可执行映像信息以及进程的页表目录指针pgd。该结构还包含有指向vm_area_struct结构的几个指针,每个vm_area_struct代表进程的一个虚拟地址区间。vm_area_struct结构含有指向vm_operations_struct结构的一个指针,vm_operations_struct描述了在这个区间的操作。 vm_operations_struct结构中包含的是函数指针,其中open、close分别用于虚拟区间的打开、关闭,而nopage用于当虚拟页面不再物理内存而引起的”缺页异常”时所调用的函数,当Linux处理这一缺页异常时,就可以为新的虚拟内存分配实际的物理内存。 每个进程都只有一个内存描述符mm_struct。在每个进程的task_struct结构中,有一个指向mm_struct的变量,这个变量常常是mm。mm_struct是对进程的地址空间(虚拟内存)的描述。一个进程的虚拟空间中可能有多个虚拟区间,对这些虚拟空间的组织方式有两种,当虚拟区较少时采用单链表,由mmap指针指向这个链表,当虚拟区间多时采用红黑树进行管理,由mm_rb指向这棵树。因为程序中用到的地址常常具有局部性,因此,最近一次用到的虚拟区间很可能下一次还要用到,因此把最近用到的虚拟区间结构放到高速缓存,这个虚拟区间就由mmap_cache指向。指针pgt指向该进程的页表目录(每个进程都有自己的页表目录),当调度程序调度一个程序运行时,就将这个地址转换成物理地址,并写入控制寄存器。由于进程的虚拟空间及下属的虚拟区间有可能在不同的上下文中受到访问,而这些访问又必须互斥,所以在该结构中设置了用于P,V操作的信号量mmap_sem。此外,page_table_lock也是为类似的目的而设置。虽然每个进程只有一个虚拟空间,但是这个虚拟空间可以被别的进程来共享。如:子进程共享父进程的地址空间,而mm_user和mm_count就对其计数。另外,还描述了代码段、数据段、堆栈段、参数段及环境段的起始和结束地址。 vm_area_struct内存描述符mm_struct指向整个地址空间,vm_area_struct只是指向了虚拟空间的一段。vm_area_struct是由双向链表链接起来的,它们是按照虚拟地址降序排序的,每个这样的结构都对应描述一个地址空间范围。之所以这样分隔是因为每个虚拟区间可能来源不同,有的可能来自可执行映像,有的可能来自共享库,而有的可能是动态内存分配的内存区,所以对于每个由vm_area_struct结构所描述的区间的处理操作和它前后范围的处理操作不同,因此linux把虚拟内存分割管理,并利用了虚拟内存处理例程vm_ops来抽象对不同来源虚拟内存的处理方法。不同的虚拟区间其处理操作可能不同,linux在这里利用了面向对象的思想,即把一个虚拟区间看成是一个对象,用vm_area_struct描述这个对象的属性,其中的vm_operation结构描述了在这个对象上的操作。  对虚拟内存区域的操作将虚拟地址关联到区域 对虚拟内存区域的操作将虚拟地址关联到区域一个虚拟地址可以通过find_vma找到与之关联的虚拟地址区域(vma) ,该函数的实现如下: /* Look up the first VMA which satisfies addr < vm_end, NULL if none. */ struct vm_area_struct *find_vma(struct mm_struct *mm, unsigned long addr) { struct rb_node *rb_node; struct vm_area_struct *vma; /* Check the cache first. */ vma = vmacache_find(mm, addr); if (likely(vma)) return vma; rb_node = mm->mm_rb.rb_node; while (rb_node) { struct vm_area_struct *tmp; tmp = rb_entry(rb_node, struct vm_area_struct, vm_rb); if (tmp->vm_end > addr) { vma = tmp; if (tmp->vm_start rb_left; } else rb_node = rb_node->rb_right; } if (vma) vmacache_update(addr, vma); return vma; }其通过搜索红黑树找到关联的区域 【文章福利】小编推荐自己的Linux内核技术交流群:【977878001】整理一些个人觉得比较好得学习书籍、视频资料;进群私聊群管理领取内核资料包(含视频教程、电子书、实战项目及代码) 内核资料直通车:Linux内核源码技术学习路线+视频教程代码资料 学习直通车:Linux内核源码/内存调优/文件系统/进程管理/设备驱动/网络协议栈 区域合并在新区域被加入进程的地址空间时,内核会检查它是否可以与一个或多个现存区域合并,该操作的实现通过函数vma_merge实现: struct vm_area_struct *vma_merge(struct mm_struct *mm, struct vm_area_struct *prev, unsigned long addr, unsigned long end, unsigned long vm_flags, struct anon_vma *anon_vma, struct file *file, pgoff_t pgoff, struct mempolicy *policy, struct vm_userfaultfd_ctx vm_userfaultfd_ctx) { pgoff_t pglen = (end - addr) >> PAGE_SHIFT; struct vm_area_struct *area, *next; int err; /* * We later require that vma->vm_flags == vm_flags, * so this tests vma->vm_flags & VM_SPECIAL, too. */ if (vm_flags & VM_SPECIAL) return NULL; if (prev) next = prev->vm_next; else next = mm->mmap; area = next; if (next && next->vm_end == end) /* cases 6, 7, 8 */ next = next->vm_next; /* * Can it merge with the predecessor? */ if (prev && prev->vm_end == addr && mpol_equal(vma_policy(prev), policy) && can_vma_merge_after(prev, vm_flags, anon_vma, file, pgoff, vm_userfaultfd_ctx)) { /* * OK, it can. Can we now merge in the successor as well? */ if (next && end == next->vm_start && mpol_equal(policy, vma_policy(next)) && can_vma_merge_before(next, vm_flags, anon_vma, file, pgoff+pglen, vm_userfaultfd_ctx) && is_mergeable_anon_vma(prev->anon_vma, next->anon_vma, NULL)) { /* cases 1, 6 */ err = vma_adjust(prev, prev->vm_start, next->vm_end, prev->vm_pgoff, NULL); } else /* cases 2, 5, 7 */ err = vma_adjust(prev, prev->vm_start, end, prev->vm_pgoff, NULL); if (err) return NULL; khugepaged_enter_vma_merge(prev, vm_flags); return prev; } /* * Can this new request be merged in front of next? */ if (next && end == next->vm_start && mpol_equal(policy, vma_policy(next)) && can_vma_merge_before(next, vm_flags, anon_vma, file, pgoff+pglen, vm_userfaultfd_ctx)) { if (prev && addr < prev->vm_end) /* case 4 */ err = vma_adjust(prev, prev->vm_start, addr, prev->vm_pgoff, NULL); else /* cases 3, 8 */ err = vma_adjust(area, addr, next->vm_end, next->vm_pgoff - pglen, NULL); if (err) return NULL; khugepaged_enter_vma_merge(area, vm_flags); return area; } return NULL; }插入区域 insert_vm_struct()创建区域 get_unmapped_area()address_space看linux内核很容易被struct address_space 这个结构迷惑,它是代表某个地址空间吗?实际上不是的,它是用于管理文件(struct inode)映射到内存的页面(struct page)的;与之对应,address_space_operations 就是用来操作该文件映射到内存的页面,比如把内存中的修改写回文件、从文件中读入数据到页面缓冲等。 也就是说address_space结构与文件的对应:一个具体的文件在打开后,内核会在内存中为之建立一个struct inode结构,其中的i_mapping域指向一个address_space结构。这样,一个文件就对应一个address_space结构,一个 address_space与一个偏移量能够确定一个page cache 或swap cache中的一个页面。因此,当要寻址某个数据时,很容易根据给定的文件及数据在文件内的偏移量而找到相应的页面 struct address_space { struct inode *host; /* owner: inode, block_device */ struct radix_tree_root page_tree; /* radix tree of all pages */ spinlock_t tree_lock; /* and lock protecting it */ atomic_t i_mmap_writable;/* count VM_SHARED mappings */ struct rb_root i_mmap; /* tree of private and shared mappings */ struct rw_semaphore i_mmap_rwsem; /* protect tree, count, list */ /* Protected by tree_lock together with the radix tree */ unsigned long nrpages; /* number of total pages */ unsigned long nrshadows; /* number of shadow entries */ pgoff_t writeback_index;/* writeback starts here */ const struct address_space_operations *a_ops; /* methods */ unsigned long flags; /* error bits/gfp mask */ spinlock_t private_lock; /* for use by the address_space */ struct list_head private_list; /* ditto */ void *private_data; /* ditto */ } __attribute__((aligned(sizeof(long))));进程地址空间布局概述虚拟地址空间主要包括以下部分: 1.当前运行代码的二进制代码text2.程序使用的动态库代码3.储存全局变量和动态产生数据的堆4.保存局部变量和实现函数/过程调用的栈5.保存环境变量和命令行参数的段6.将文件内容 映射到虚拟地址空间的内存映射  0~3G的用户空间。从小到大(从下往上)依次为:保留区(受保护的地址)、代码段、数据段(.data段)、.bss段、堆空间、内存映射段、栈空间、命令行参数和环境变量。下面依次对每一个段做简单的介绍: 组成部分介绍1.保留区(受保护的地址) 保留区即为受保护的地址,大小为0~4K,位于虚拟地址空间的最低部分,未赋予物理地址(不会与内存地址相对应,因此其不会放任何内容)。任何对它的引用都是非法的,用于捕捉使用空指针和小整型值指针引用内存的异常情况。大多数操作系统中,极小的地址通常都是不允许访问的,如NULL。C语言将无效指针赋值为0也是出于这种考虑,因为0地址上正常情况下不会存放有效的可访问数据。将指针赋值为0,意味着该指针将永远不会被使用,从而不会出现野指针情况。#define NULL 0 与 #define NULL (void*)0 在C语言中是等效的,而在C++中,只能用#define NULL 0,后面 #define NULL (void*)0的使用会出错。 2.代码段 代码段也称正文段或文本段,通常用于存放程序执行代码(即CPU执行的机器指令)。一般C语言执行语句都编译成机器代码保存在代码段。通常代码段是可共享的,因此频繁执行的程序只需要在内存中拥有一份拷贝即可。代码段通常属于只读,以防止其他程序意外地修改其指令(对该段的写操作将导致段错误)。某些架构也允许代码段为可写,即允许修改程序。 3.数据段(.data段) 数据段通常用于存放程序中已初始化的全局变量和静态局部变量。数据段属于静态内存分配(静态存储区),可读可写。由于全局变量未初始化时,其默认值为0,因此值为0的全局变量位于.bbs段(不位于数据段)。对于未初始化的局部变量,其值是不可预测的。注意:在代码段和数据段之间还包括其它段:只读数据段和符号段等。 4…bss段 该段用于存放未初始化的全局变量和静态局部变量,包括值为0的全局变量。 数据段和.bss段又称为全局数据区,前者初始化,后者未初始化。 ELF段包括:代码段、其它段(只读数据段和符号段等)、.data段(数据段)和.bss段,都属于可执行程序部分。 5.堆空间 new( )和malloc( )函数分配的空间就属于堆空间,用于内存空间的分配,其从下往上。 堆用于存放进程运行时动态分配的内存段,可动态扩张或缩减。堆中内容是匿名的,不能按名字直接访问,只能通过指针间接访问。当进程调用malloc© 和new (C++)等函数分配内存时,新分配的内存动态添加到堆上(扩张);当调用free©/delete(C++)等函数释放内存时,被释放的内存从堆中剔除(缩减) 。 6.内存映射段(共享库) 此处,内核将硬盘文件的内容直接映射到内存, 任何应用程序都可通过Linux的mmap()系统调用请求这种映射。内存映射是一种方便高效的文件I/O方式, 因而被用于装载动态共享库。如C标准库函数(fread、fwrite、fopen等)和Linux系统I/O函数,它们都是动态库函数,其中C标准库函数都被封装在了/lib/libc.so库文件中,都是二进制文件。这些动态库函数都是与位置无关的代码,即每次被加载进入内存映射区时的位置都是不一样的,因此使用的是其本身的逻辑地址,经过变换成线性地址(虚拟地址),然后再映射到内存。而静态库不一样,由于静态库被链接到可执行文件中,因此其位于代码段,每次在地址空间中的位置都是固定的。 7.栈空间 用于存放局部变量(非静态局部变量,C语言称为自动变量),分配存储空间时从上往下。栈和堆都是后进先出的数据结构。 8.命令行参数 该段用于存放命令行参数的内容:argc和argv。 9.环境变量 用于存放当前的环境变量,在Linux中用env命令可以查看其值。 10.虚拟地址空间的作用(好处) 1.方面编译器和操作系统安排程序的地址;2.方便实现各个进程空间之间的隔离,互不干扰,因为每个进程都对应自己的虚拟地址空间;3.实现虚拟存储,从逻辑上扩大了内存。 补充内容: 代码段(.text段)与只读数据段和符号段(.rodata段),都属于只能读的部分,在链接的时候这两部分会链接成为一个整体;而.data段和.bbs段属于可读可写RW的部分。这四个部分都是以页(每页4KB)的形式存放在内存中。进程控制块PCB(又叫进程描述符)放于内核空间。 多个进程在并发执行时,这些进程的用户空间都是彼此独立的,因此各个进程的用户空间在映射为内存空间使都是独立的,互不干扰,这是MMU地址变换必须要能够保证的。例如,各个进程的.text段、只读数据段和符号段、.data段和.bbs段等在用户空间中使用到的其它数据信息,都会与页为基本单位放在内存中,各个进程的映射是独立的。而对于内核空间,由于只有一个操作系统,内核空间主要是 机器指令、操作系统内核的各个模块等,它们是公用的,因此每个进程的映射方式一样。强调一点:每个进程用到或即将用到的数据才会调入内存,其余都在磁盘上。但是各个进程内核空间的进程控制块(进程描述符)映射的地点是不一样的,也是相互独立的。共用的模块才是一样的。 这些都是MMU的实现机制所决定的。如果感兴趣,可以看看MMU的实现机制。 虚拟内存区域的组织上面介绍了Linux 进程虚拟地址空间的组成部分,但这些组成部分是如何组织在一起的呢?它们又是如何被进程管理的呢?下面我们就来回答这些问题: 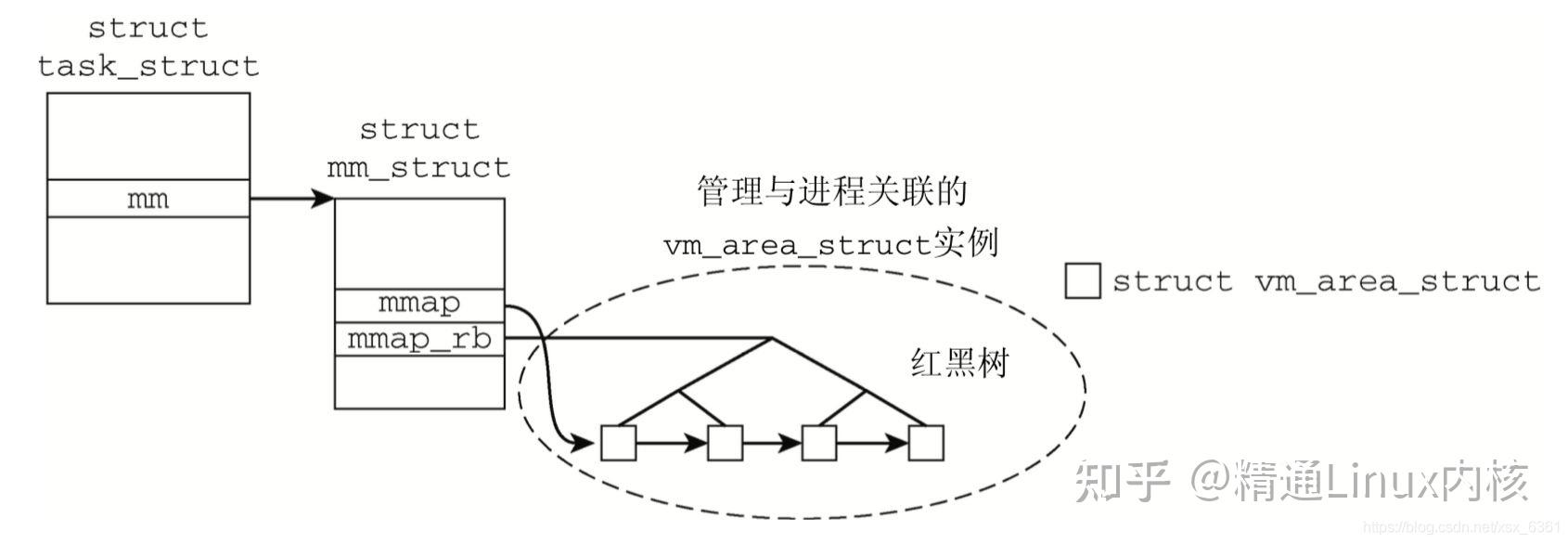 如上图所示,每个进程对应一个task_struct结构体,该结构体保存了进程的重要信息,其中就包括进程的内存信息—mm_struct。mm_struct则保存了进程所在的虚拟内存的位置信息,它里面有两个重要的指针—mmap和mmap_rb,这两个指针以不同的方式指向了进程的虚拟内存区域vm_area_struct,也被称为VMA。进程的各个段,比如代码段、数据段、BSS段甚至是mmap映射的区域都保存在VMA中。VMA通过两种方式来管理,一是mmap指向的双向链表,VMA按照起始地址递增的顺序被归到链表中,方便管理;而是mmap_rb指向的红黑树,红黑树的每个叶子结点就是一个VMA区域,引入红黑树的好处是可以提高查找VMA的效率(即便VMA的数量翻倍,VMA的查找次数也只增加一次)。一个虚拟地址可以通过find_vma找到它所属的VMA区域。 内存映射由于所有用户总的虚拟地址空间比实际可用的物理内存大得多,因此只有最常用的内存页才与物理页帧相关联。而在读写硬盘文件时,并不需要将整个文件都拷贝到内存中,所以内核必须提供一种虚拟地址空间和相关数据所在位置的关联机制来提高读写硬盘数据的效率。而这个机制就是内存映射 。  内核实现内存映射的系统调用是mmap(),它有两种实现,一种是将硬盘文件直接映射到虚拟地址空间;另外一种是不映射硬盘文件而是直接申请一段内存,这也是c库中malloc()会调用的方式。malloc()在申请小于128k的内存时使用brk(),而在申请大于128k的内存时使用mmap()。 反向映射之前我们可以通过页表机制建立虚拟地址和物理地址的联系。但是我们无法通过一个物理页找到它所有关联的进程。在内核进行页换出的时候,它必须要在确保该页的所有引用为0的情况下才能将改页换出。那么如何通过一个物理页来找到其关联的进程从而确定其引用次数呢?内核通过反向映射机制解决了这个问题。实际上,在很古老的内核中是通过遍历所有进程内存描述来确认这个问题的,这显然效率不够高,为了解决这个问题,在物理内存的描述结构 struct 中,有一个 mapping 属性,它可能指向两种对象,一个是 address_space 它对应的是通过文件映射方式产生的虚拟内存,另一个是 anon_vma 它对应的是匿名内存(堆栈等) struct page { ... union { struct { ... struct address_space *mapping; // 如果最低位为 0,则指向 inode address_space,或者为 NULL。如果页映射为匿名内存,最低位为 1,而且该指针指向 anon_vma 对象。 } ... ... }基于文件的映射我们先来介绍一下文件映射的情况,address_space 是如何组织内存区域(vm_area_struct)的呢?内核使用了一个被称为优先查找树的结构来组织。  简单来讲,基于文件映射产生的物理页会包含一个struct address_space,该结构体中的i_mmap指向了组织各个引用该物理页的虚拟内存区域的优先树,而虚拟内存区域又与mm_struct相关。优先树用来管理表示给定文件中特定区间的所有 m_area_struct 实例,因为不同进程可能映射同一个文件的不同位置。这要求该数据结构不仅能够处理重叠,还要能处理相同的文件区间。 匿名映射匿名内存的处理相对来说比较简单,它不需要处理映射文件不同位置的问题,所以就没有了优先树,这时候 page 的 mapping 指向了一个链表 anon_vma,该链表包含了所有使用该物理页的虚拟地址空间区域。  原文作者:首页 - 内核技术中文网 - 构建全国最权威的内核技术交流分享论坛 原文地址:Linux内核:进程管理--进程虚拟内存管理 - 圈点 - 内核技术中文网 - 构建全国最权威的内核技术交流分享论坛(版权归原文作者所有,侵权留言联系删除) 
|
【本文地址】